I’m in London, at one of those funny little tech workspaces you find in most big cities. This place calls itself a post-accelerator, hosts boot camps and hackathons, has a living wall, a spotless kitchen (albeit with a coffee machine that’s on the blink), and lots of millennial males in large headphones tapping away at keyboards.
I am not here, however, for a bit of face time with a callow techie man-child. I've come to meet a man of the world, a television war reporter-turned-entrepreneur named Jeff Kofman. He’s the CEO and cofounder of Trint, a startup that set out to slay the dragon of many a journalist: transcription. Kofman describes this part of the journalistic process, even in a digital world, as "play, stop, type, rewind. Play, stop, type . . . the same tedious process."
Stop. Rewind a few years. In 2013, Kofman had followed a tip from a friend and visited Mozfest, the annual open web summit in London. One of the prototypes on display was a project called Hyperaud.io, using text as a basis for remixing audio and video, and which was being sponsored by the Knight Foundation.
"It was one of those moments when a lightbulb goes on over your head," he says. That drag-and-drop editing, as we call it, was the thing that really blew me away." Kofman realized that this concept could revolutionize not just his industry but other sectors, including education and even perhaps medicine.
And with Cisco currently estimating 84% of web communication to be audio and video, the impact could be huge. Solving the problem of turning recorded conversations into text could transform how we consume podcasts, radio, and video, and open up a century of oral histories to researchers and amateur historians.

Others have been working hard on the problem. While we've seen rapid improvements on our smartphones and in various other speech-to-text features—pioneered by Nuance’s Dragon Naturally Speaking and found in services like Google Docs—more functional transcription has been a persistent challenge, even for the most sophisticated neural networks. Researchers at companies like IBM, Microsoft, Google, and Baidu are working hard on reducing error rates, testing various systems under stress conditions like high winds, background music, regional accents, and over-the-phone conversations.
Kofman—who had won Emmys for his coverage of the World Trade Center attacks and the Libyan revolution—was determined to make it work, in an easy-to-use product geared toward journalists. He began raising some "modest" seed capital, and in November 2014, the day after he left journalism for good, flew to Florence to hole up in an Airbnb with the three developers behind the original idea, Mark Boas, Laurian Gridinoc, and Mark Panaghiston. Within three months they had built the first prototype that worked, albeit clumsily. The second version kept freezing and crashing, and Panaghiston painstakingly rebuilt the editor to incorporate audio, video, text, and word timings.
Combine the powers of all voice-recognition systems together—including systems by Google, Microsoft, and IBM—and the error rate is currently at around 8%. Work with a human transcriptionist on the phone and you’re looking at an error rate of 4%.
The service uses existing software for its speech recognition. But Trint's cofounders are mum about what that software is. (It may or may not be telling that Google, which has made its own speech-recognition API freely available, awarded the startup a grant via its Digital News Initiative Innovation Fund). Boas, now Trint’s CTO, meets my question about the technology with, "We are not able to disclose."
Trint isn't perfect. If you’re looking for something anywhere close to perfection, you will need near-perfect audio, no background noise, no regional accents (good luck): Trint echoes the old computing adage about garbage in, garbage out: "Better audio means better transcription." Boas reckons that the biggest test for the software is to "prepare the expectations of the user."
Speech recognition is one area where the brain—"an amazing piece of equipment," he says—is mightier than the machine. If you were to combine the powers of all voice-recognition systems together—including systems by Google, Microsoft, and IBM—and train that on a conversation in English (which includes a quarter-million distinct words, and sometimes parentheticals like this one), you'd get an error rate at around 8%. Work with a human transcriptionist on the phone and you’re looking at an error rate of 4%.
"Our brains are very good at deciphering audio of the spoken word in all sorts of situations," says Boas. "The artificial intelligence that does this stuff is not as good as our brains, so there is this kind of misunderstanding about how good the algorithm is."
After you’ve "trinted" an audio file—the name, a combination of transcription and interview, is meant to be both verb and noun—it is up to you to check the transcript with the audio, which is easily done, thanks to the audio player that runs beneath the text document. "We make it easy for users to to cover those last yards," says Kofman. It's this that makes Trint unique among transcription solutions. "We are the first to find a way to push A.I. this far," he reckons. "We like to say that Trint does the heavy lifting, and by glueing the audio and video to a text editor, the Trint Editor makes it easy for users to polish their transcripts to perfect. It's a challenge to explain because it's a new concept: near-perfect transcripts."
Less difficult to explain is the cost. Human-based transcription tends to cost about $1 a minute. Trint brings that down to about 25¢. TranscribeMe, a human-based transcription service, charges 79¢ per hour and relies upon an army of transcriptionists that it recruits online, sharing-economy style. The humans are paid at least $20 per audio hour, and earn an average of $250 a month, the company says. Other companies include GoTranscript, and Voci, which grew out of research at Carnegie Mellon University and provides voice transcription and analytics for enterprise customers.
Jeff, known as Beta Tester No. 1 by the tech team, has suggested all sorts of tools to make the process easier. There are playback speed controls, there’s a button that allows you to rewind the conversation five seconds. The software inserts time indicators in the text editor, and attempts to compensate for regional accents; it also offers transcription into European Spanish, French, and German. You can highlight text and turn that into video captions—perfect for preparing a video clip for social media—as well as export the finished transcript, or just the highlights, into formats suitable for text, audio, and video documents.
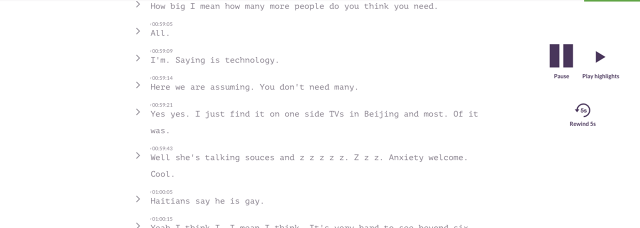
"It takes between three to four hours for an experienced human to transcribe one hour of audio," says Kofman. "If you want, say, four moments in an hour of conversation, we can free you up to between 75% and 90% of your time." When I tested the system by uploading an audio file of a 28-minute interview, the text-audio version came back in four minutes. For my interview with Jeff, who was in the meeting room with me, the Trint came back with around 85% accuracy. But whenever Mark's words appeared on the Trint (he was chatting with us through WebEx, his voice being piped through speakers a yard or so away from my recorder), it was total jibber-jabber—see below. Again, this fits with the notion, says Boas, of "good quality in, good quality out."
In a comment posted earlier this month on the blog of Luigi Benetton, a copywriter and journalist based in Toronto, a person purporting to be "a transcriptionist by trade" said she was "less then impressed" by Trint. "The only possible scenario I can imagine is a lecture given in pristine conditions by someone who never pauses except at the ends of sentences, has an American English Midwestern accent (my clear speaker was from Seattle . . . and Trint consistently misheard the same words as something else), and where there is no background noise. Possibly students would find this useful, where inaccuracies wouldn’t matter since they know the content."
"No journalist, researcher, lawyer, or business person would trust that output without verifying it," says Kofman. "That process of verification is inefficient and time consuming: You need to relisten to the entire recording or search for the moment you want to check. By the time you do that, you'll probably find old-fashioned manual transcription is just as efficient." Because of the manpower involved, the price is around $1 per minute (although one firm, iScribed, offers a rate of 89¢ per minute. One of Trint's clients was previously paying around $110 per hour. And so, for media firms, Trint is a bargain compared with human-based transcription services. Depending on volume, the pricing is $15 per hour for casual users on Trint's Pay-As-You-Go Plan, or 25¢ per minute. For company accounts with larger volumes, the price drops to $10 per hour, but Kofman points out that pricing will change "as we begin to roll out features for instant captioning, social media sharing, and more."
Google's grant was given to push through three specific features to fruition, and the team is hoping to roll them out throughout 2017. The first is a one-click caption service that allows the user to caption videos without the usual headaches that it entails. There is drag-and-drop editing, enabling journalists to create a package of highlights in minutes. There is also an embedded Trint video player that will allow viewers to search for the relevant section just by typing a term into a box. The real jewel of this innovation is that it will finally render web audio and video searchable, and allow social media users to write posts that feature the relevant clip, rather than the entire file.
Although the Trint product is aimed at consumers, Kofman expects media organizations to provide the company with the business it needs to grow. His team has identified six verticals where Trint and its "transcripts you can trust" could bring in revenue: besides media, Trint has seen interest from other sectors including education, corporate communications, and marketing, as well as medicine, law, and law enforcement. "We are already in discussion with justice officials and law enforcement to define how Trint could meet their needs," he says. One growing challenge for police is how to catalog hours of video captured on in-car and body-worn cameras. "Law and justice are under huge pressure to reduce costs, and manual transcription is a huge line item for both."
With its 11 employees, Trint is still agile enough to react to specific requests of its clients, which include ESPN and Vice. When one U.S.-based broadcaster requested the team build in a time-related feature that allows users to enter a timecode offset that is applied to all transcript timings, the team was able to build it in as a bespoke feature. Trint is also working on one-click captioning.
"News organizations are always telling us they spend huge amounts of resources transcribing these captions, inputting them and then attaching them to the video. People want custom fonts, they want to be able to use their own style guide. So many people have asked us for that so we know these are areas to monetize."
Kofman says that customers from the education and corporate sectors who have who have tried out Trint are jumping for joy that the service cuts transcription costs and frees up the budget for something more meaningful. The end result, he thinks, will be "making people more efficient and liberating them to focus on what their job really is, which is creating original content." For his part, the former war correspondent-turned-entrepreneur says he doesn't miss his old profession much; besides, he now faces a problem that he's trying to save journalists and others from: "I don't have time," he says.
Originally published here.
We’re always happy to chat about the innovative tech we work on here at Trint, so don’t hesitate to get in touch with us for all media enquiries at victoria@trint.com.









